Email newsletters are so last season. But the AI field moves fast enough that staying current feels mandatory and staying sane feels impossible.
We have a particular version of the problem. I'm a product manager who builds with AI tooling all day; Miyuki is almost a year into a software development career. The same news matters to the two of us but from different angles. Even though we both speak Japanese as well as English, we each read most comfortably in our native language.
One thing we have recently been frustrated about is the increasing phone use. News are a time sink and learning what's going on forces a lot of screen time; we wanted something that did the scrolling for us overnight and handed each of us, in our own language, the three-to-five things that genuinely mattered to us - and then got out of the way.
Problem & Opportunity
The pain is information triage under two constraints most tools ignore: personal relevance and language.
Generic AI newsletters optimize for a median reader who is neither of us. An RSS feed reader solves discovery but not ranking - it hands you everything and makes you the filter, which is the work we wanted to remove. Translation tools turn English news into stiff Japanese but don't decide what's worth translating in the first place. And nothing on the market understands that a single household can contain two people with different jobs, different fluencies, and different definitions of "relevant" reading the same morning.
So the job I want done is: When I start my day, help me understand what in AI and tech actually matters to me - in my language, without doomscrolling - so I can stay sharp without drowning in noise.
The opportunity wasn't a market opportunity; it was a personal one to help me keep up with a field that is accelerating fast. A genuinely useful daily tool for two real users, and an honest testbed for a question I was also curious to answer: can I run local AI models on an ~$80 computer and what would that look like today?
Solution
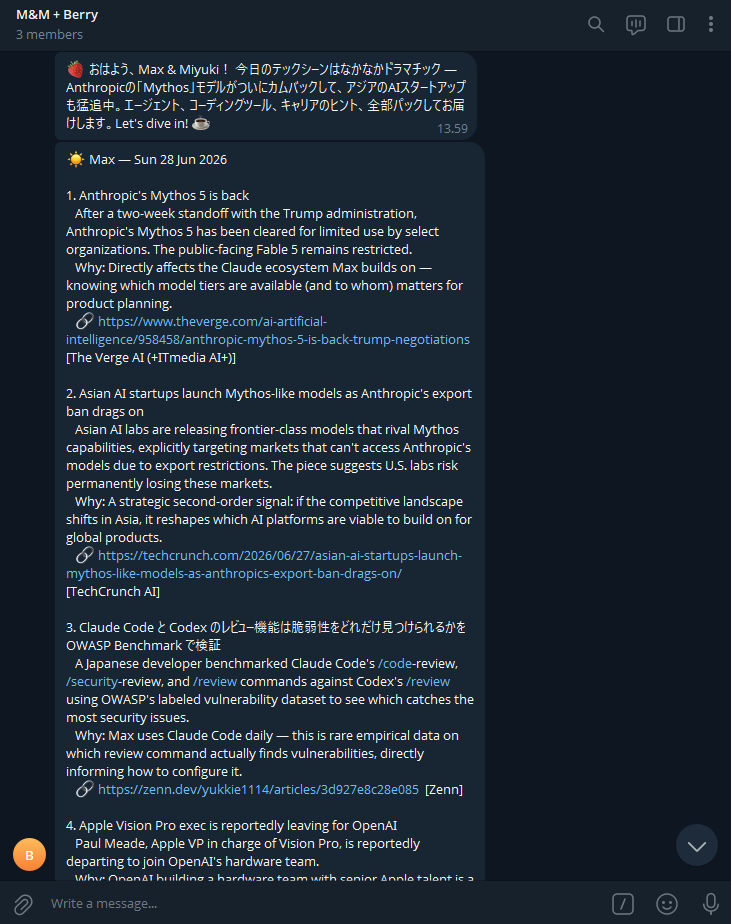
Berry is a nightly pipeline wrapped in an always-on agent. The output is three Telegram messages that land in a shared family group every morning:
- A short shared opener - a warm good-morning and the day's overall vibe, written in a deliberately funky Japanese/English mix heavy on katakana loanwords. It gives Berry a personality and gives both of us something we each half-read.
- My brief, in English - three to five stories ranked against my profile (AI agents, model releases, dev tooling, product strategy, with a soft spot for space and index investing), each with a one-line "why this matters to you" and a source link.
- Miyuki's brief, in Japanese - three to five stories ranked against hers (where the software industry is heading, concrete skills, AI's impact on dev jobs framed as opportunity rather than doom), drawing partly from Japanese-language dev sources she'd never see in an English feed.
Under the hood it's a three-tier pipeline:
- Tier 0 - plain scripts, no LLM. A fetcher pulls sixteen curated RSS feeds, normalizes them, deduplicates against a local SQLite store so yesterday's news never resurfaces, and balances the candidate set across sources so a high-volume feed can't crowd out a quiet primary one. Zero tokens, fully deterministic.
- Tier 2 - one constrained cloud call. The deduplicated candidates and the two human-readable profile files go to Claude Sonnet in a single budget-capped call that returns the structured, ranked, bilingual brief. This is the only step that needs real judgment, so it's the only step that pays for it.
- Delivery - plain scripts again. A small sender posts the three messages to Telegram directly via the Bot API, with retries to ride out flaky moments.
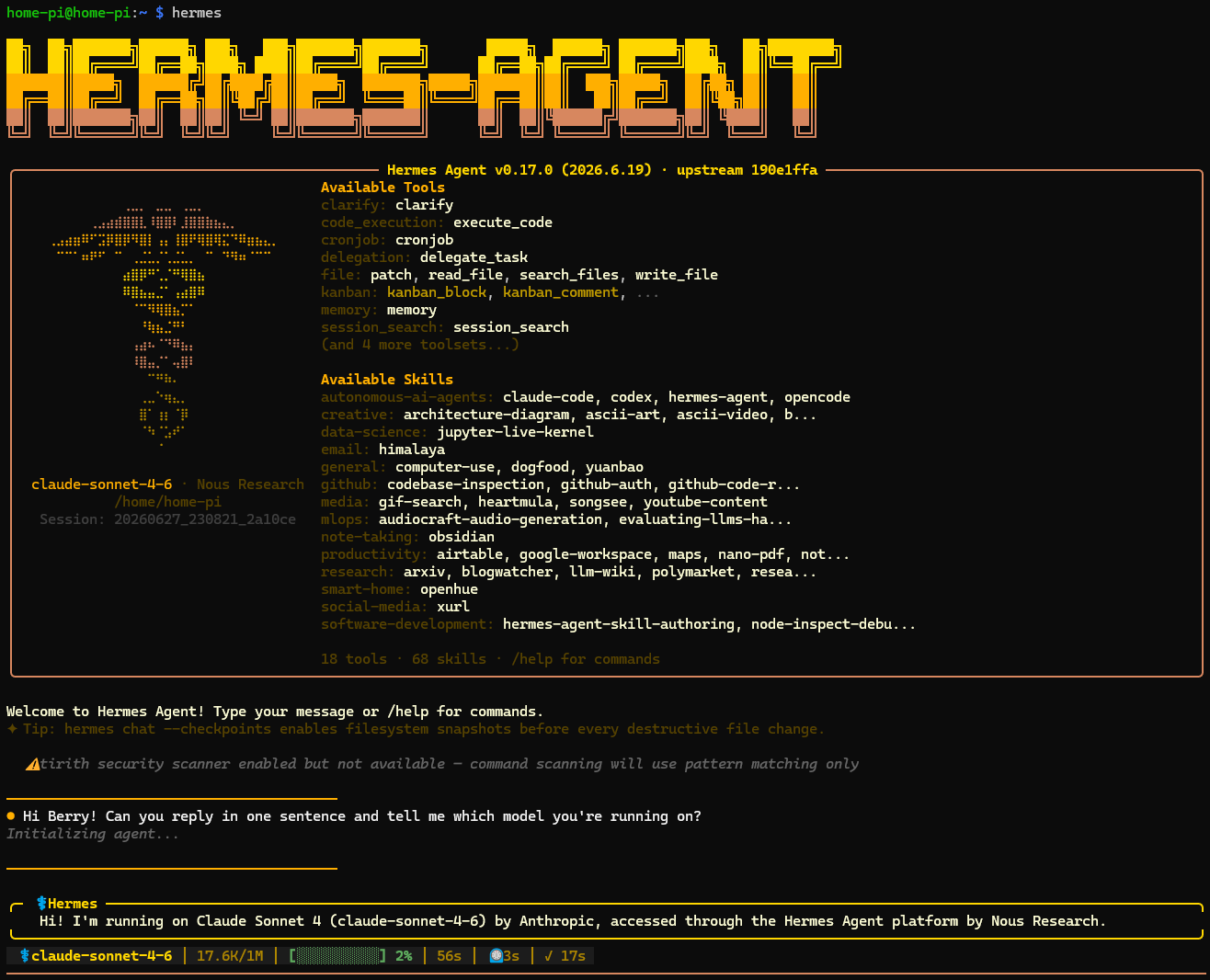
The whole pipeline is triggered by the Hermes Agent runtime's built-in scheduler as a no-LLM cron job at 07:30 JST; a non-zero exit DMs me privately so a silent failure can't happen. Per-person relevance is driven by two plain Markdown profile files I can edit in a text editor - no retraining, no database. Remote access is over Tailscale; the heavy synthesis runs against my own Anthropic API key.
The design principle throughout: the agent writes; scripts do everything else. More on why below (because I actually wanted to do something different initially but ran into some issues).
The Local-vs-Cloud Decision
The premise I most wanted to test: a Raspberry Pi 5 with 8GB of RAM can run a small language model locally via Ollama, so how much of Berry could run for free on the device, with the cloud reserved only for the heavy lifting?
I benchmarked it honestly before deciding. Gemma 3 4B (quantized) on the Pi ran at ~4.5 tokens/second with an ~8.8-second cold load - fine for an overnight batch, painfully slow for anything interactive, where a single multi-step agent turn would run into minutes. Small models are also unreliable at the tool-calling that an agent loop depends on. Meanwhile the only genuinely model-heavy task in the whole system - the bilingual, per-person synthesis - is exactly the one where quality is non-negotiable, so it seemingly has to be cloud regardless.
The uncomfortable and frankly boring insight that fell out of the benchmark: most of Berry isn't an LLM job at all. Fetching, deduplicating, formatting, and delivering are deterministic code. The "free because it's local" savings I'd imagined mostly came from realizing those steps never needed a model in the first place. So the architecture became: scripts for the mechanical 80%, one constrained Sonnet call for the judgment, and the local model on the bench - not because local is useless, but because in this system its only honest home is non-time-critical batch work (like grading the eval, a planned next step), not the critical path. Documenting that decision, with the number that drove it, was as much the point of the project as the briefs themselves.
(One adjacent decision worth noting: I run synthesis through my own metered API key, not a consumer subscription. Anthropic's consumer terms prohibit automated, programmatic access through Pro/Max accounts - the sanctioned path for an always-on agent is the API. It's also the only path that gives me a clean per-night cost number and a hard spend cap.)
Target Audience
The entire user base is two people in one apartment, which is exactly why it's a good test.
Me - the over-informed builder. A senior Product Manager who lives in the AI tooling and needs actionable knowledge, not headlines: what a release means for the products and roles I think about, digested fast enough that I'm not the last to know (as I feel I often am). Low tolerance for fluff, high tolerance for density.
Miyuki - the early-career navigator. Eight months into software development, reading the same "AI is going to replace engineers" headlines I do but with real career stakes underneath them. Her brief has a deliberate editorial stance baked into her profile: clear-eyed about where the industry is heading, but framed around concrete skills and opportunities - never doom. That framing is a product decision, not sugar-coating: she asked for the honest picture, and the honest picture is more useful when it's actionable.

AIニュースめっちゃいい感じ - Miyuki
Berry is days old, so the honest "result" isn't a usage chart — it's a working system, its economics, and a set of decisions and findings I can defend.
- It ships. A full bilingual, per-person, deduplicated, cited brief lands on schedule, end to end, with no human in the loop.
- It's cheap. ~0.05€ per night in Claude tokens - roughly 1.5€/month — bounded by a per-run token cap and a hard monthly spend limit on the API key. The local-model experiment means there's a clear, costed answer to "should this run on-device?" rather than a vibe.
- It measures itself. I built a small eval harness around three questions I care about more than engagement: relevance precision (a thumbs up/down per item, so I can ask what fraction of what Berry served actually mattered, per person, over a week), novelty (a check that proves the dedup store isn't resurfacing old items), and source-accuracy (a model-graded check that each summary faithfully represents its source rather than embellishing).
The most interesting result, though, is a negative one I didn't expect, and it's the best thing the project taught me - see the first learning below.
What's next is the same instinct that drove the project: close the loop. Run the local-vs-cloud experiment for real by having the Pi's Gemma model grade source-accuracy head-to-head against cloud Haiku (agreement, latency, cost - actual numbers behind the routing decision); widen and tune the source list against a week of relevance data; and revisit the in-the-moment feedback UX now that I know its constraints.
Learnings
The agent was the wrong tool for the agent's own busywork. Berry's headline finding. The Hermes agent writes genuinely good bilingual briefs - but when I tried to have it log a one-tap thumbs-up from Telegram into a file, it repeatedly ignored the instruction and reverted to being a helpful chatbot ("could you paste item 3 so I can tune future briefs?"). Two increasingly explicit rules didn't fix it; its conversational instinct kept winning over the structured side-task. The fix was to take the agent out of that loop entirely and capture feedback with a tiny deterministic script. The lesson generalizes: use the agent for judgment, not for plumbing. Anything that needs to happen reliably and identically every time belongs in code, not in a model's conversational lap.
Cloud for judgment, scripts for everything else - and hardware romanticism loses to a benchmark. I wanted the local model on the Pi to be the star. The honest measurement (4.5 tok/s) said otherwise, and following it led to a better architecture than the one I'd imagined: deterministic scripts for the 80% of the system that was never really an LLM problem, and a single constrained cloud call for the part that is. The most valuable thing the local model produced was the number that told me where it didn't belong.
"Structured output" isn't structured until you force it to be. Getting Claude to emit two parallel arrays of bilingual items reliably was the single hardest engineering problem in the build. The model would intermittently stringify one array, slip an unescaped quote into Japanese text, or drop the second list - each failure shipping an empty brief for one of us. The robust fix was a combination: a single flat, person-tagged list instead of two arrays, plus a repair-parser to recover the malformed JSON the model occasionally emits anyway. Treat LLM structured output as probably-valid and build the defensive layer before you trust it in production.


No items found.
Check Out My Other Projects

Statistically Employable | Tech Job Market Tracker
A free web tool that shows career switchers and bootcamp students which tech skills Finnish employers are actually hiring for — city by city, updated weekly, with real job posting data instead of global rankings.
View Case Study

App of Empires | Design of a Web App
A "virtual coach" for players of the 20-year old classic RTS, Age of Empires 2, for improving gameplay.
View Case Study

